9 Critical Database Design Best Practices for 2025
Explore our definitive guide to database design best practices. Master normalization, indexing, security, and scalability with 9 actionable tips.

In modern application development, the database is more than just a storage container; it is the fundamental backbone supporting your system's performance, reliability, and scalability. A well-designed database accelerates development, prevents bugs, and scales gracefully as user demand grows. Conversely, a poorly designed schema almost guarantees slow queries, data corruption, and crippling technical debt that can stall progress for months or even years. The initial design choices you make have long-term consequences, impacting everything from application speed to maintenance costs.
This guide bypasses theoretical jargon and gets straight to the point. We have compiled a comprehensive list of actionable database design best practices to help you build a solid foundation. You will learn not just what to do, but why it matters and how to implement it correctly from the start.
We will cover essential techniques ranging from foundational principles like normalization and data integrity to advanced strategies involving indexing, security, and planning for future growth. Each point is designed to be practical, providing clear steps you can apply immediately to your projects. Whether you are a CTO at a growing enterprise, a product manager aiming for a high-performance MVP, or a developer tasked with resolving technical debt, these insights will equip you to build robust, efficient, and future-proof database architectures. Let's start building a blueprint for a system that not only works but thrives under pressure.
1. Normalize Your Database Structure
One of the most foundational database design best practices is normalization. Pioneered by Edgar F. Codd, this process organizes data to minimize redundancy and improve data integrity. It involves dividing large, unwieldy tables into smaller, more manageable ones and defining clear relationships between them. This prevents issues like data anomalies, where updating information in one place fails to update it elsewhere, leading to inconsistencies.
The process follows a series of guidelines known as normal forms, from First Normal Form (1NF) to Fifth Normal Form (5NF). For most practical business applications, achieving Third Normal Form (3NF) provides a robust balance between data integrity and performance. In 3NF, every non-key attribute of a table must depend on the primary key, and nothing but the primary key. This structure makes the database more efficient, easier to maintain, and less prone to errors.
Why Normalization Matters
A normalized database significantly reduces the amount of storage space needed by eliminating duplicate data. For example, instead of storing a customer's full address with every single order they place, you store the address once in a Customers table and link it to the Orders table via a customer ID. This not only saves space but also simplifies updates; if a customer moves, you only need to update their address in one location.
This infographic illustrates the core goals of database normalization, connecting the central concept to its primary benefits.
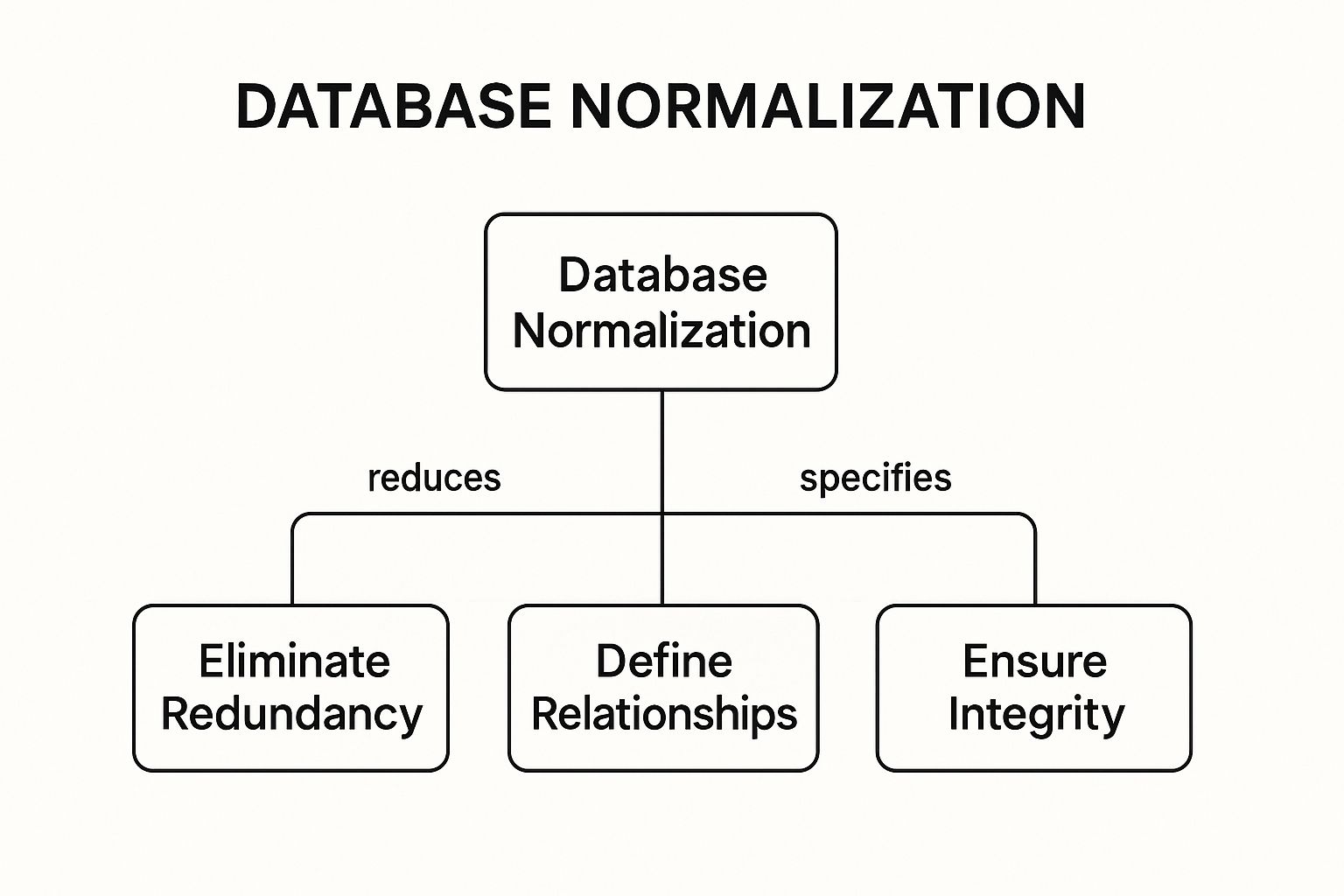
As the concept map highlights, the process is fundamentally about creating a logical, efficient structure that eliminates redundancy, defines clear relationships, and ultimately ensures data integrity.
Actionable Tips for Normalization
- Target 3NF: For most business systems, aiming for Third Normal Form is the standard. It provides a strong foundation without the complexities of higher forms.
- Visualize with ERDs: Use Entity-Relationship Diagrams (ERDs) to map out your tables and their relationships. This visual tool helps clarify how data is connected and exposes potential design flaws.
- Denormalize Strategically: While normalization is key, sometimes performance requires denormalization (intentionally violating normal forms). Only consider this for read-heavy applications after identifying specific performance bottlenecks with profiling tools.
This video provides a practical explanation of normalization concepts and how to apply them.
2. Use Appropriate Data Types and Constraints
Another core component of effective database design best practices is selecting the right data types and constraints. This involves choosing the most efficient and suitable type for each column (e.g., INTEGER, VARCHAR, DECIMAL) based on the nature of the data it holds. Additionally, applying constraints like NOT NULL, UNIQUE, and CHECK enforces business rules directly within the database, safeguarding data integrity from the ground up.
This practice ensures that data is stored efficiently, validated automatically, and processed quickly. For instance, using a DATE type for a birthdate instead of a VARCHAR not only saves space but also allows for proper date calculations and sorting. By enforcing rules at the schema level, you create a reliable foundation that prevents invalid data from ever entering your system, reducing the need for complex application-level validation logic.
Why Data Types and Constraints Matter
Proper data type selection directly impacts storage efficiency and query performance. Storing a number in a text field, for example, consumes more space and makes mathematical operations significantly slower. Constraints act as the database's immune system, preventing corrupt or inconsistent data. A CHECK constraint on an order_quantity column can ensure it's always a positive number, while a UNIQUE constraint prevents duplicate email addresses in a Users table.
This level of control at the database layer is critical for maintaining data quality as an application scales. It establishes a single source of truth for business rules, ensuring that no matter how the data is entered or modified, it adheres to predefined standards. This approach simplifies development and makes the entire system more robust and predictable.
Actionable Tips for Data Types and Constraints
- Choose the Smallest Fit: Use the smallest data type that safely accommodates your data range. For example, use
TINYINTinstead ofINTfor a value that will never exceed 255. - Use DECIMAL for Money: Never use
FLOATorREALfor financial calculations due to potential rounding errors.DECIMALorNUMERICtypes are designed for exact precision. - Enforce
NOT NULL: ApplyNOT NULLconstraints to any column that must always contain a value. This is a simple but powerful way to prevent missing data issues. - Leverage CHECK Constraints: Use
CHECKconstraints to enforce specific business rules, like ensuring an email address contains an "@" symbol or that a product's price is non-negative. - Define Foreign Keys: Always define
FOREIGN KEYconstraints to maintain referential integrity between related tables. This prevents "orphaned" records, such as an order that belongs to a non-existent customer.
This video offers a detailed guide on choosing the right data types in SQL, covering the trade-offs and performance implications.
3. Establish Clear Naming Conventions
Implementing consistent and descriptive naming conventions is a foundational database design best practice that dramatically improves maintainability, clarity, and collaboration. This approach involves creating a standardized set of rules for naming tables, columns, indexes, constraints, and other database objects. A well-defined naming strategy makes the database schema self-documenting, reducing ambiguity and accelerating development by making it intuitive and predictable.
When a new developer joins your team, they shouldn't need a decoder ring to understand that cust_ord_dt means "customer order date." Clear conventions, such as using snake_case (e.g., user_repositories) or PascalCase (e.g., CustomerOrders), remove guesswork and enforce a professional standard. This consistency is a simple yet powerful tool for reducing cognitive load and preventing common errors.
Why Naming Conventions Matter
A coherent naming strategy is the bedrock of a scalable and manageable database. It ensures that anyone interacting with the schema can quickly understand the purpose of a table or the data held within a column without constantly referring to documentation. This accelerates onboarding, simplifies debugging, and makes writing complex queries more straightforward.
For example, consistently naming foreign keys like user_id or product_id immediately clarifies relationships between tables. Similarly, prefixing indexes with idx_ and primary keys with pk_ provides instant insight into the database's structure and performance optimization strategies. This level of clarity is crucial in team environments where multiple developers and data analysts work on the same system.
Actionable Tips for Naming Conventions
- Document Everything: Create a schema design guide that outlines all naming rules and make it accessible to the entire team. This document should be the single source of truth.
- Be Consistent with Pluralization: Choose one convention for table names (e.g., plural
users,products) and stick to it. The Ruby on Rails convention of using plural table names and singular model names is a popular standard. - Use Descriptive Prefixes: Clearly identify object types. Use prefixes like
fk_for foreign keys,idx_for indexes, andvw_for views to make your schema easier to navigate. - Avoid Reserved Words: Never use SQL reserved keywords (like
SELECT,TABLE,GROUP) as names for your tables or columns. This is a common source of confusing syntax errors. - Make Booleans Clear: Name boolean columns as questions that can be answered with true or false, such as
is_active,has_shipped, orcan_edit.
This video discusses the importance of conventions and provides practical examples for creating a robust naming strategy.
4. Design for Query Performance with Proper Indexing
One of the most impactful database design best practices is strategic indexing. An index is a special lookup table that the database search engine can use to speed up data retrieval. Think of it like the index in the back of a book; instead of reading every page to find a topic, you can look it up in the index to go directly to the correct page. This process drastically reduces the time it takes to execute queries, especially on large datasets.
Proper indexing involves identifying columns that are frequently used in WHERE clauses, JOIN conditions, and ORDER BY clauses. By creating an index on these columns, you allow the database to locate the required rows quickly without performing a full table scan. For example, Amazon indexes product_name and category_id to make its product search feature lightning-fast. The key is to balance the significant boost in read performance against the slight overhead that indexes add to write operations like INSERT, UPDATE, and DELETE.

Why Proper Indexing Matters
Without indexes, a database must scan every single row in a table to find the data that matches a query's criteria. This is slow and resource-intensive, leading to poor application performance and a frustrating user experience. As a table grows, the time it takes to complete these scans increases linearly, making the application progressively slower.
Strategic indexing is crucial for scalability. For instance, LinkedIn indexes user profiles by skills, location, and industry, enabling its job matching and search features to work efficiently across millions of profiles. Neglecting this practice often leads to performance bottlenecks that are difficult to resolve later. Addressing poor indexing early on is a key strategy to reduce technical debt and ensure long-term system health.
Actionable Tips for Indexing
- Analyze Query Patterns: Use tools like
EXPLAINor query execution plans to identify slow queries and determine which columns would benefit most from an index. Focus on columns inWHERE,ORDER BY, andGROUP BYclauses. - Index Foreign Keys: Always create indexes on foreign key columns. This dramatically speeds up
JOINoperations, which are common in relational databases. - Use Composite Indexes Wisely: For queries that filter on multiple columns, create a composite index. Place the most selective column (the one with the most unique values) first in the index definition for maximum efficiency.
- Avoid Over-Indexing: Don't index every column. Each index consumes storage and adds overhead to write operations. A good rule of thumb is to keep the number of indexes per table between three and five.
- Maintain Your Indexes: Periodically monitor index usage to identify and remove any that are no longer used. Additionally, rebuild or reorganize indexes that have become fragmented over time to maintain optimal performance.
5. Plan for Scalability and Future Growth
Designing a database with scalability in mind is a crucial practice that ensures your system can handle increasing data volumes, user loads, and complexity without requiring a complete and costly overhaul. This forward-thinking approach involves anticipating growth patterns, choosing appropriate data types that allow for expansion, and designing flexible schemas. It considers both vertical scaling (adding more power to an existing server) and horizontal scaling (distributing the load across multiple servers).
Effective scalability planning prevents painful migrations and system rewrites as your application grows. Companies like Instagram and Pinterest built their massive platforms on this principle, using sharding to distribute user data across countless database instances. This partitioning strategy allows them to handle billions of records and requests while maintaining high performance, a feat that would be impossible with a single, monolithic database.
Why Scalability Matters
A scalable database design directly impacts your application's long-term viability and cost-effectiveness. Without it, initial success can quickly lead to performance degradation, system crashes, and poor user experience as load increases. Proactively planning for growth means your infrastructure can expand gracefully, accommodating more users and data with predictable costs and effort.
This approach is also foundational to maintaining a competitive edge. It allows you to add new features and handle traffic spikes without being constrained by your initial architectural decisions. For businesses facing the challenge of an aging system, understanding how to modernize legacy applications is key to implementing these scalable designs.
Actionable Tips for Scalable Design
- Choose Appropriate Primary Keys: Use
BIGINTfor primary keys in high-growth tables, even if you don't need the capacity immediately. Integer-based keys generally outperform UUIDs for indexing at scale. - Implement Partitioning Early: Plan your partition (or sharding) keys carefully based on your most common query patterns. For example, partition user data by geographic region or a user ID range to distribute the load logically.
- Use Read Replicas: Offload read-heavy queries to one or more read replicas. This simple strategy significantly reduces the burden on your primary database, improving overall responsiveness for write operations.
- Design for Statelessness: Ensure your application layer is stateless. This allows you to easily add more application servers to handle increased traffic, as any server can process any user request without relying on local session data.
6. Implement Proper Security and Access Controls
Database security is a non-negotiable aspect of modern application development. This critical practice involves protecting sensitive data from unauthorized access, breaches, and malicious activities through multiple layers of defense. It encompasses authentication to verify user identities, authorization to define what users can do, encryption to protect data at rest and in transit, and auditing to track database activities. A core tenet of this approach is the principle of least privilege, which ensures users and applications are granted only the minimum permissions necessary to perform their functions.
Integrating security into your database design from the very beginning is far more effective than trying to add it as an afterthought. For example, financial institutions like those using Microsoft SQL Server’s Always Encrypted technology can ensure sensitive credit card numbers are protected even from database administrators. Similarly, multi-tenant SaaS applications like Salesforce implement robust field-level security to ensure one customer cannot access another’s data, making security a foundational component of the architecture.

Why Security and Access Controls Matter
Proper security controls are the first line of defense against data breaches that can lead to devastating financial losses, reputational damage, and legal penalties. By implementing features like row-level security, as popularized by PostgreSQL, you can ensure that users only see the data they are explicitly permitted to view. This is essential for applications handling confidential information, such as healthcare systems needing to maintain HIPAA compliance.
Furthermore, a strong security posture builds trust with users and customers, assuring them that their personal information is safe. While this section focuses on database-specific controls, a comprehensive security strategy also includes broader website security measures to protect the entire application and its data.
Actionable Tips for Database Security
- Prevent SQL Injection: Use prepared statements and parameterized queries in your application code. This is one of the most effective ways to stop malicious SQL from being executed against your database.
- Hash Passwords Correctly: Never store passwords in plain text. Use strong, modern hashing algorithms like bcrypt or Argon2 to securely store user credentials.
- Encrypt Sensitive Data: Identify and encrypt columns containing personally identifiable information (PII), financial records, or health data. Use transparent data encryption (TDE) for data at rest and TLS/SSL for data in transit.
- Use Roles for Permissions: Instead of granting permissions directly to individual user accounts, create roles with specific privileges (e.g.,
readonly,data_entry,admin) and assign users to those roles. This simplifies permission management and reduces errors. - Regularly Audit and Update: Routinely review user access logs and permissions to identify suspicious activity. Keep your database management system (DBMS) updated with the latest security patches.
7. Maintain Data Integrity with Relationships and Constraints
One of the most critical database design best practices is establishing rules that ensure the accuracy and consistency of your data. This is achieved through data integrity, which involves using relationships and constraints to enforce business rules directly within the database schema. By defining foreign key relationships, you create a direct, enforceable link between related tables, preventing data inconsistencies like "orphaned" records that reference non-existent entities.
For instance, an Orders table would have a foreign key linking to the Customers table. This constraint makes it impossible to create an order for a customer who does not exist in the system. Edgar F. Codd’s relational model laid the groundwork for this concept, known as referential integrity. It’s a powerful, declarative way to ensure your data remains logical, reliable, and trustworthy as it evolves.
Why Data Integrity Matters
Enforcing data integrity at the database level provides a single source of truth for your business rules, preventing invalid data from ever being saved, regardless of the application trying to insert it. This is far more robust than relying solely on application-level validation, which can be bypassed or implemented inconsistently across different services. It prevents common errors, such as a product being assigned to a non-existent category or a transaction being recorded without a valid account.
This approach builds a solid foundation for your application, ensuring that relationships between entities like users, posts, accounts, and contacts are always valid. This makes the system more predictable, easier to debug, and significantly more reliable. It directly protects the core value of your database: the quality and accuracy of the information it holds.
Actionable Tips for Data Integrity
- Define Foreign Keys: Always define foreign key constraints to formally link related tables. This is the primary mechanism for enforcing referential integrity.
- Choose Cascade Actions Wisely: Use actions like
ON DELETE CASCADE,SET NULL, orRESTRICTbased on clear business logic. Be extremely cautious withCASCADE, as it can lead to unintentional mass deletions. - Use Soft Deletes: For critical data, consider a "soft delete" approach by adding an
is_deletedflag instead of physically removing rows. This preserves historical data and avoids complex cascading effects. - Document Your Choices: Clearly document the reasoning behind your referential integrity rules and chosen cascade actions to help future developers understand the system's behavior.
This video offers a clear explanation of database relationships and the importance of foreign keys in maintaining data integrity.
8. Document Your Database Schema and Design Decisions
Comprehensive documentation is one of the most critical yet often overlooked database design best practices. It involves creating and maintaining a clear record of your database schema, design choices, business rules, and architectural rationale. This practice transforms implicit knowledge into an explicit, shared resource, ensuring the long-term maintainability and scalability of your system. Without it, a database becomes a cryptic black box, making future updates, troubleshooting, and developer onboarding incredibly difficult.
A well-documented database serves as a central source of truth for the entire engineering team. It clarifies the purpose of each table, the meaning of every column, and the intricate relationships that connect them. Leading tech companies like GitLab and Stripe have built their success on a foundation of transparent, thorough documentation, which empowers developers to build and innovate with confidence. It’s the blueprint that guides both current and future development efforts.
Why Documentation Matters
Clear documentation significantly reduces the time it takes for new team members to become productive. Instead of deciphering table names or guessing at column purposes, they can consult a data dictionary or an Entity-Relationship Diagram (ERD). This also minimizes the risk of introducing bugs or data inconsistencies when modifying the schema, as the impact of changes becomes much easier to understand.
Furthermore, documenting the "why" behind your decisions-such as choosing to denormalize a specific table for performance-provides invaluable context. This historical record prevents future developers from "correcting" intentional design choices, ensuring that hard-won performance optimizations are not accidentally undone. A deep dive into technical documentation best practices can reveal how this discipline supports the entire software development lifecycle. For a more comprehensive look, you can learn more about technical documentation best practices on 42coffeecups.com.
Actionable Tips for Documentation
- Document in Place: Use your database's native commenting features (e.g.,
COMMENT ON TABLEin PostgreSQL) to embed descriptions directly within the schema itself. - Maintain a Data Dictionary: Create a centralized document that lists every table and column, its data type, constraints, and a clear, human-readable description of its purpose.
- Visualize with ERDs: Use tools like dbdiagram.io, Lucidchart, or draw.io to create and maintain Entity-Relationship Diagrams. A visual map is often the fastest way to understand data relationships.
- Use Version Control: Store your schema definition files (SQL DDL) and documentation in a Git repository. This allows you to track changes over time and link schema updates to specific feature tickets.
- Automate Where Possible: Leverage tools like SchemaSpy or SchemaCrawler to automatically generate documentation from your live database, which helps keep your records up-to-date with minimal effort.
9. Optimize with Denormalization When Appropriate
While normalization is a cornerstone of sound database design, there are specific scenarios where intentionally breaking these rules, a practice known as denormalization, is a powerful optimization strategy. Denormalization involves introducing calculated or redundant data into a table to speed up read-heavy query performance. By adding this data, you can reduce the number of expensive joins required to retrieve information, which is a common performance bottleneck in highly normalized databases.
This approach is a trade-off. You sacrifice some write efficiency and data integrity safeguards for significant gains in read speed. For example, instead of calculating a post's vote count every time it's displayed, a platform like Reddit might store the total count directly on the post record. This makes fetching the data for a popular feed incredibly fast, as the database avoids a complex aggregation query across a massive Votes table for every single post.
Why Denormalization Matters
In high-traffic applications where read operations vastly outnumber write operations, the performance benefits of denormalization can be critical. Systems like YouTube cache view counts, and e-commerce sites often store a customer's name directly on an Orders table. This avoids joining to the Customers table just to display a simple order history, leading to a much faster user experience.
This approach is one of the key database design best practices for scaling applications. When a perfectly normalized schema cannot meet performance requirements, strategic denormalization allows the architecture to evolve. It is a conscious, data-driven decision to prioritize speed where it matters most, ensuring the application remains responsive under heavy load.
Actionable Tips for Denormalization
- Profile First: Only denormalize after you've identified a specific performance bottleneck through query profiling. Don't do it preemptively.
- Maintain Consistency: Use database triggers, application-level logic, or background jobs to keep redundant data synchronized. For example, when a new order is placed, a trigger can copy the customer's name into the
Orderstable. - Consider Materialized Views: Before altering table structures, see if your database supports materialized views. They offer a way to store pre-computed query results without physically changing your core schema.
- Document Everything: Clearly document which parts of your schema are denormalized and the mechanisms used to maintain data consistency. This is crucial for future maintenance.
- Evaluate Read/Write Ratios: Denormalization is most effective for workloads that are heavily skewed towards reads. If writes are frequent, the overhead of keeping redundant data in sync might negate the performance gains.
Best Practices Comparison Matrix
| Aspect | Normalize Your Database Structure | Use Appropriate Data Types and Constraints | Establish Clear Naming Conventions | Design for Query Performance with Proper Indexing | Plan for Scalability and Future Growth | Implement Proper Security and Access Controls |
|---|---|---|---|---|---|---|
| Implementation Complexity 🔄 | Medium to High: requires deep understanding of normal forms and relationships | Medium: requires careful upfront planning of types and constraints | Low: requires team agreement and documentation | High: needs expertise in index types and query analysis | High: involves complex planning for growth and distribution | High: involves multiple layers of security and ongoing maintenance |
| Resource Requirements ⚡ | Moderate: more tables and joins increase workload | Low to Moderate: mostly design-time effort | Low: mainly documentation efforts | Moderate to High: increased storage and maintenance overhead | Moderate to High: infrastructure and management resources | Moderate to High: additional security tools and monitoring required |
| Expected Outcomes 📊 | ⭐⭐⭐⭐⭐ Improves data integrity, reduces redundancy, easier maintenance | ⭐⭐⭐⭐ Ensures data accuracy, improves performance, enforces rules | ⭐⭐⭐ Improves readability, collaboration, faster onboarding | ⭐⭐⭐⭐⭐ Dramatically faster queries and efficient data access | ⭐⭐⭐⭐ Supports growth without major redesign, better performance | ⭐⭐⭐⭐ Protects data, ensures compliance, reduces risk |
| Ideal Use Cases 💡 | Systems requiring strong data integrity and minimal redundancy | All databases needing correctness and validation | Teams collaborating on long-term projects | Read-heavy applications with complex queries | Applications expecting growth and higher load | Any system handling sensitive or regulated data |
| Key Advantages ⭐ | Reduces anomalies, storage savings, scalable schemas | Data accuracy, prevents invalid entries, better query speed | Consistency, maintainability, reduces confusion | Query speed, resource savings, better user experience | Future-proofing, supports scaling methods | Data protection, regulatory compliance, audit trails |
| Key Disadvantages ⚠ | Complex queries and joins, possible performance hit on reads | Harder to change schema, possible overhead on writes | Requires consensus, can be verbose | Slower writes, storage cost, maintenance complexity | Planning overhead, possible over-engineering | Potential performance impact, added complexity and costs |
| Aspect | Maintain Data Integrity with Relationships and Constraints | Document Your Database Schema and Design Decisions | Optimize with Denormalization When Appropriate |
|---|---|---|---|
| Implementation Complexity 🔄 | Medium: involves defining constraints and cascading rules | Low to Medium: requires discipline and ongoing effort | Medium to High: requires performance analysis and balancing |
| Resource Requirements ⚡ | Moderate: constraint checks and referential enforcement | Low: mostly documentation effort, tool support available | Moderate: increased storage and logic for synchronization |
| Expected Outcomes 📊 | ⭐⭐⭐⭐ Prevents data corruption, consistent relationships | ⭐⭐⭐ Improves understanding, onboarding, and collaboration | ⭐⭐⭐⭐ Improves read performance, reduces complex queries |
| Ideal Use Cases 💡 | Databases with relational data and complex dependencies | Projects with multiple developers and evolving schemas | Read-heavy systems with identified performance bottlenecks |
| Key Advantages ⭐ | Reliable data, automatic enforcement of business rules | Reduced errors, knowledge preservation, easier maintenance | Faster queries, less server load, better reporting support |
| Key Disadvantages ⚠ | Potential performance impact on large operations | Requires upkeep, risk of outdated info | Increased redundancy, complex updates, risk of inconsistencies |
Building Your Next Great Application on a Solid Foundation
The journey through database design best practices reveals a fundamental truth: a database is not merely a storage unit. It is the architectural backbone of your application, the engine that powers its performance, and the vault that secures your most valuable asset, your data. Treating its design as an afterthought is like building a skyscraper on a foundation of sand; initial progress may seem fast, but the structure is destined to falter under pressure.
We've explored a comprehensive set of principles, from the logical elegance of normalization to the pragmatic necessity of strategic denormalization. We've seen how choosing the correct data types and enforcing constraints acts as the first line of defense for data integrity. A disciplined approach to naming conventions and thorough documentation transforms a complex schema from an arcane puzzle into a clear, collaborative blueprint that your entire development team can understand and build upon.
From Theory to Tangible Results
The real value of mastering these concepts lies in their collective impact. A well-designed database doesn’t just work; it excels.
- Performance is a Feature: Proper indexing isn't a minor tweak; it's the difference between sub-second query responses and a frustrating user experience. It's the key to making your application feel fast, responsive, and reliable.
- Security is Non-Negotiable: Implementing robust security and access controls from the outset isn't about paranoia; it's about building trust with your users and protecting your business from catastrophic breaches.
- Scalability is Foresight: Planning for future growth ensures that your success doesn't become your biggest technical problem. A scalable design allows your application to handle a surge in users and data gracefully, without requiring a complete, costly overhaul.
By internalizing these database design best practices, you shift from a reactive mode of fixing problems to a proactive mode of preventing them. You build a system that is not only powerful today but also resilient and adaptable for the challenges of tomorrow.
Your Actionable Path Forward
Moving from knowledge to implementation is the most critical step. Don't let this be just another article you read. Instead, use it as a catalyst for immediate action.
- Audit Your Current Project: Take one of your existing databases and evaluate it against the principles we've discussed. Where are the gaps? Is indexing insufficient? Are naming conventions inconsistent? A small, focused audit can reveal significant opportunities for improvement.
- Create a Design Checklist: For your very next project, create a simple checklist based on the key takeaways from this guide. Before a single table is created, ensure you have a plan for normalization, naming, indexing, and security.
- Champion Documentation: Make documentation a required part of your development workflow. Start today. Document one key table in your existing schema, explaining its purpose, its columns, and its relationships. This small habit builds a culture of clarity.
Ultimately, investing time and effort into a solid database architecture is one of the highest-leverage activities a development team can undertake. It pays continuous dividends in the form of faster performance, easier maintenance, fewer bugs, and enhanced security. This strong foundation empowers you to focus on what truly matters: building innovative features and delivering exceptional value to your users.
Ready to transform your database from a performance bottleneck into a strategic advantage? At 42 Coffee Cups, we specialize in building high-performance, scalable web applications with an expert focus on Python/Django and Next.js, all built upon a foundation of impeccable database architecture. Let our team of seasoned experts help you design, build, or modernize your application's data layer for long-term success.